Interval povjerenja
Što je interval povjerenja:
To je procjena raspona koji se koristi u statistici, koji sadrži parametar populacije. Ovaj nepoznati parametar populacije nalazi se na uzorku modela izračunatog iz prikupljenih podataka .
Primjer: prosjek prikupljenog uzorka x̅ može ili ne mora odgovarati pravoj populacijskoj sredini μ. U tu svrhu moguće je razmotriti raspon uzoraka koji mogu sadržavati ovu populaciju. Što je taj interval duži, veća je vjerojatnost da će se to dogoditi.
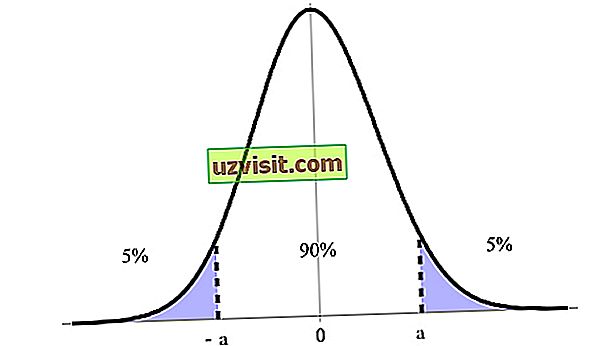
Interval pouzdanosti je izražen kao postotak, izražen razinom pouzdanosti, pri čemu je najviše naznačeno 90%, 95% i 99%. Na slici ispod, na primjer, imamo 90% intervala pouzdanosti između njegovih gornjih i donjih granica (a i -a ).
Interval povjerenja je jedan od najvažnijih pojmova u testiranju hipoteza u statistici, jer se koristi kao mjera nesigurnosti. Pojam je uveo poljski matematičar i statističar Jerzy Neyman 1937.
Koji je značaj intervala povjerenja?
Interval pouzdanosti važan je za označavanje granice nesigurnosti (ili nepreciznosti) u odnosu na izračun. Ovaj izračun koristi uzorak istraživanja za procjenu stvarne veličine rezultata u izvornoj populaciji.
Izračun intervala pouzdanosti je strategija koja uzima u obzir uzorkovanje pogrešaka. Veličina ishoda vaše studije i vaš interval povjerenja karakteriziraju pretpostavljene vrijednosti za izvornu populaciju.
Što je interval povjerenja uži, veća je vjerojatnost da postotak ispitivane populacije predstavlja stvarni broj populacije izvora, što daje veću sigurnost o ishodu predmeta istraživanja.
Kako interpretirati interval povjerenja?
Ispravno tumačenje intervala pouzdanosti vjerojatno je najizazovniji aspekt ovog statističkog koncepta. Primjer najčešćeg tumačenja koncepta je sljedeći:
Postoji vjerojatnost od 95% da u budućnosti prava vrijednost parametra populacije (npr. Prosjek) pada u rasponu X (donja granica) i Y (gornja granica).
Stoga se interval pouzdanosti interpretira na sljedeći način: 95% je uvjereno da interval između X (donja granica) i Y (gornja granica) sadrži pravu vrijednost parametra populacije.
Bilo bi potpuno pogrešno tvrditi da: postoji 95% vjerojatnost da interval između X (donja granica) i Y (gornja granica) sadrži stvarnu vrijednost parametra populacije.
Gornja izjava je najčešća zabluda o intervalu pouzdanosti. Nakon izračunavanja statističkog raspona može sadržavati samo populacijski parametar ili ne.
Međutim, intervali mogu varirati između uzoraka, dok je stvarni parametar populacije isti bez obzira na uzorak.
Stoga se izjava pouzdanosti intervala pouzdanosti može napraviti samo u slučaju kada se intervali pouzdanosti ponovno izračunavaju za broj uzoraka.
Koraci izračunavanja intervala pouzdanosti
Raspon se izračunava pomoću sljedećih koraka:
- Prikupite podatke uzorka: n ;
- Izračunajte srednju vrijednost uzorka x̅;
- Odredite je li standardna devijacija populacije ( σ ) poznata ili nepoznata;
- Ako je poznata standardna devijacija populacije, z- točka se može koristiti za odgovarajuću razinu pouzdanosti;
- Ako je standardna devijacija populacije nepoznata, možemo koristiti statistiku t za odgovarajuću razinu pouzdanosti;
- Stoga se donja i gornja granica intervala pouzdanosti nalaze pomoću sljedećih formula:
a) Standardna devijacija poznate populacije :
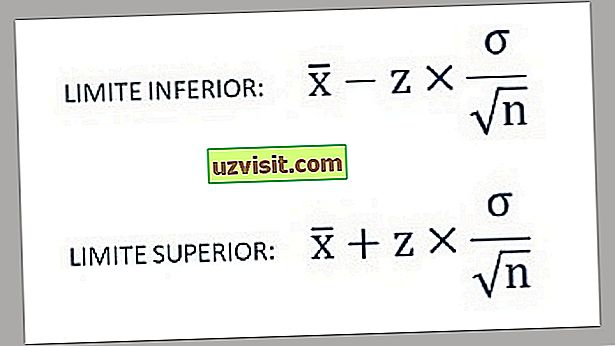
Formula za izračunavanje standardne devijacije poznate populacije.
b) Standardna devijacija nepoznate populacije :

Formula za izračun standardne devijacije nepoznate populacije.
Praktični primjer intervala pouzdanosti
Klinička studija procijenila je povezanost između prisutnosti astme i rizika od razvoja opstruktivne apneje u snu kod odraslih.
Neke odrasle osobe nasumce su odabrane s popisa državnih dužnosnika koje treba pratiti četiri godine.
Sudionici s astmom, u usporedbi s onima bez njih, imali su veći rizik razvoja apneje tijekom četiri godine.
U provođenju kliničkih istraživanja kao što je ovaj primjer, podskup populacije od interesa se obično regrutira kako bi se povećala učinkovitost istraživanja (manje troškova i manje vremena).
Ova podskupina pojedinaca, proučavana populacija, sastoji se od onih koji zadovoljavaju kriterije uključivanja i pristaju na sudjelovanje u studiji, kao što je prikazano na slici ispod.

Zatim, studija je dovršena i izračunava se veličina učinka (npr. Srednja razlika ili relativni rizik ) kako bi se odgovorilo na istraživačko pitanje.
Ovaj proces, koji se naziva zaključivanje, uključuje korištenje podataka prikupljenih od ispitivane populacije kako bi se procijenila veličina stvarnog učinka na populaciju od interesa, odnosno populaciju podrijetla.
U danom primjeru, istraživači su zaposlili slučajni uzorak državnih službenika (populacija izvora) koji su bili prihvatljivi i pristali sudjelovati u studiji (ispitivana populacija) i izvijestili da astma povećava rizik od razvoja apneje u ispitanoj populaciji.
Kako bi se uzela u obzir pogreška uzorkovanja uslijed zapošljavanja samo podskupine interesne populacije, izračunali su i 95% interval pouzdanosti (oko procjene) od 1, 06 do 1, 82, što ukazuje na vjerojatnost 95 % da je pravi relativni rizik u izvornoj populaciji između 1, 06 i 1, 82 .
Interval povjerenja za prosjek
Kada se dobije podatak o standardnoj devijaciji populacije, može se izračunati interval pouzdanosti za prosjek ili prosjek te populacije.
Kada je statistička karakteristika koja se mjeri (kao što je dohodak, IQ, cijena, visina, količina ili težina) numerička, u većini slučajeva procjenjuje se da je pronađena prosječna vrijednost za populaciju.
Stoga pokušavamo pronaći prosječnu populaciju ( μ ) koristeći prosječnu srednju vrijednost ( x̅ ), s marginom pogreške. Rezultat ovog izračuna naziva se interval pouzdanosti za srednju vrijednost populacije .
Kada je poznata standardna devijacija populacije, formula za interval pouzdanosti (CI) za srednju populaciju je:

gdje je:
- x̅ znači uzorak;
- σ je standardna devijacija populacije;
- n veličina uzorka;
- Represents * predstavlja odgovarajuću vrijednost standardne normalne distribucije za željenu razinu pouzdanosti.
Slijede vrijednosti za različite razine pouzdanosti () * ):
| Razina povjerenja | Vrijednost Z * - |
|---|---|
| 80% | 01:28 |
| 90% | 1.645 (uobičajeno) |
| 95% | 1.96 |
| 98% | 02:33 |
| 99% | 02:58 |
Gornja tablica prikazuje z * vrijednosti za dane razine pouzdanosti. Napominjemo da se te vrijednosti dobivaju iz standardne normalne distribucije (Z-).
Područje između svake z * vrijednosti i negativ ove vrijednosti je (približni) postotak pouzdanosti. Na primjer, površina između z * = 1, 28 i z = -1, 28 je približno 0, 80. Stoga se ova tablica može proširiti i na druge postotke povjerenja. Tablica prikazuje samo najčešće korištene postotke povjerenja.
Vidi također značenje hipoteze.